El corazón de los chatbots: qué es realmente un Data Store en Google Cloud
Cómo funcionan los Data Stores en Google Cloud para chatbots tipo RAG, por qué hay que crearlos primero por fuera y qué evitar en producción.

En este artículo
Google Cloud va a la vanguardia con sus productos, lo cual es hermoso para el cliente que disfruta de la última moda tecnológica. Pero para los que estamos tras el escenario, mantenerse actualizado es un reto diario. En este artículo vamos a desentrañar el misterioso mundo de los Data Stores. No porque sea física cuántica nuclear, sino porque la documentación oficial no es tan amigable, qué raro.
Chatbots a la carta
Paréntesis rápido: ¿qué es un chatbot tipo RAG? Imagina que un chatbot normal es como un estudiante que va a dar un examen de memoria; a veces se pone nervioso y empieza a inventar cosas (lo que en IA llamamos “alucinar”). Un chatbot tipo RAG (Generación Aumentada por Recuperación) es como ese mismo estudiante, pero con el examen a libro abierto. Cuando tú le preguntas algo, el bot corre al Data Store (el libro), busca la página exacta con la respuesta correcta, la lee en un milisegundo y te la explica con sus propias palabras. Así no se inventa información.
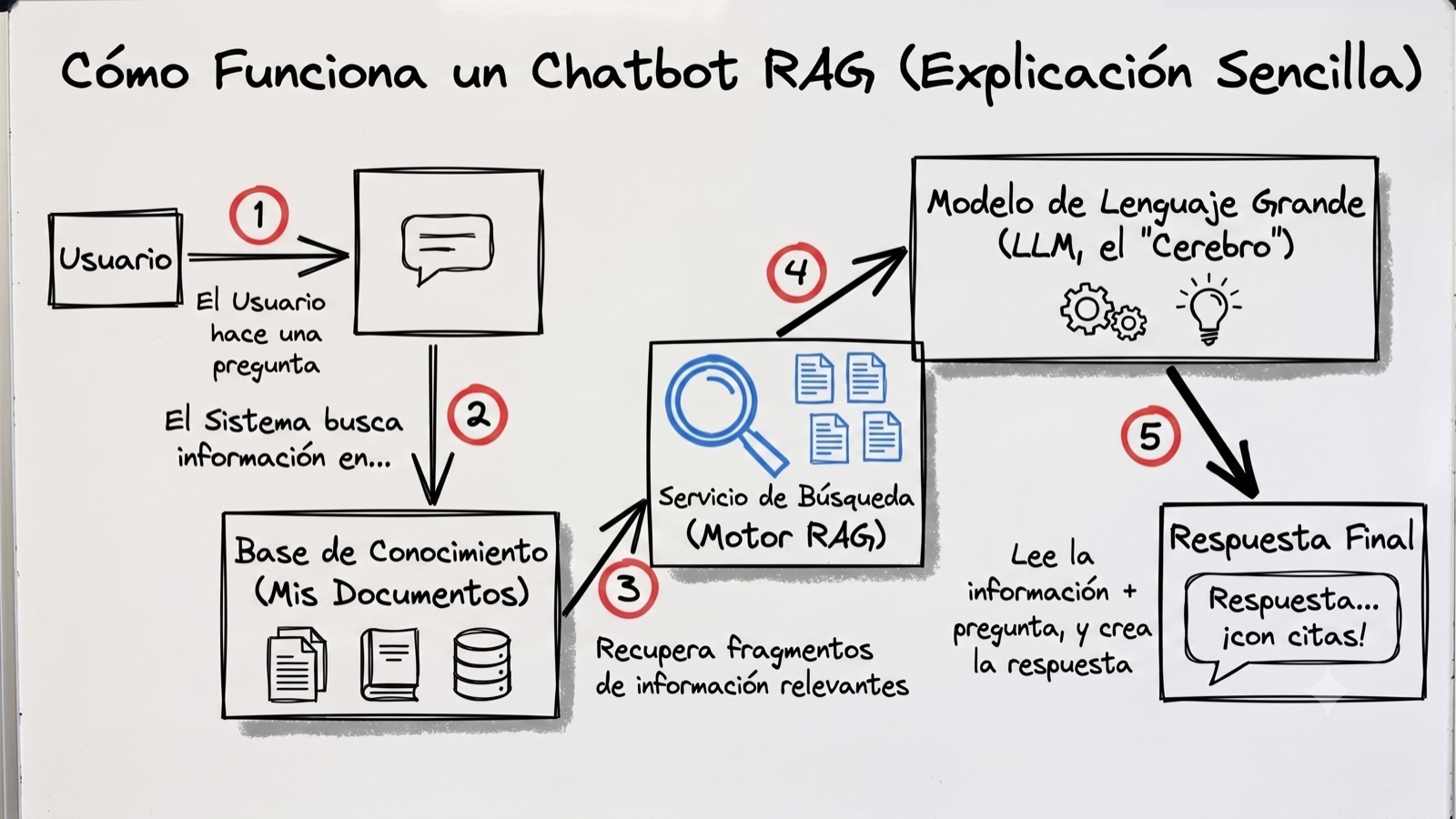
¡Una vez más! Todo comienza con el pedido para la construcción de un chatbot tipo RAG que sirva información actualizada a los clientes (se refresque en tiempo real). Así que me puse manos a la obra. Hace no mucho, la solución obvia era un servicio llamado Dialogflow CX. Esta herramienta nos permite construir chatbots que se alimentan de cualquier fuente de datos y nos da el control total de qué responder y cómo actuar.
Pero como es típico de Google, si no te cambian los nombres de sus productos dos veces al año no son ellos, hoy este ecosistema ha digievolucionado. Para entender estos nuevos nombres en el terreno de batalla, Google Cloud se divide en dos grandes ramas dentro de sus soluciones de IA:
AI Applications — Search and assistant (chatbots buscadores): es para cuando no queremos que el chatbot hable como loro. Es literalmente poner una barra de búsqueda tipo Google en tu web o donde desees, pero que solo busque dentro de tus datos. Es decir, el usuario escribe algo y el sistema busca el documento o el link exacto. Dentro de AI Applications, al crear una app, esta opción aparece como la pestaña “Search and assistant” con varios sabores: búsqueda general, búsqueda para sitios web, búsqueda para datos de salud, entre otros.
AI Applications — Conversation agents (chatbots conversacionales): aquí es donde está el futuro difunto Dialogflow CX. Esta es la herramienta efectiva para cuando queremos que nuestro chatbot sea interactivo. El bot saluda, conversa, mantiene el hilo de la charla y parece más inteligente que nosotros, y nos brinda herramientas nativas para integrarse con otros canales como WhatsApp.
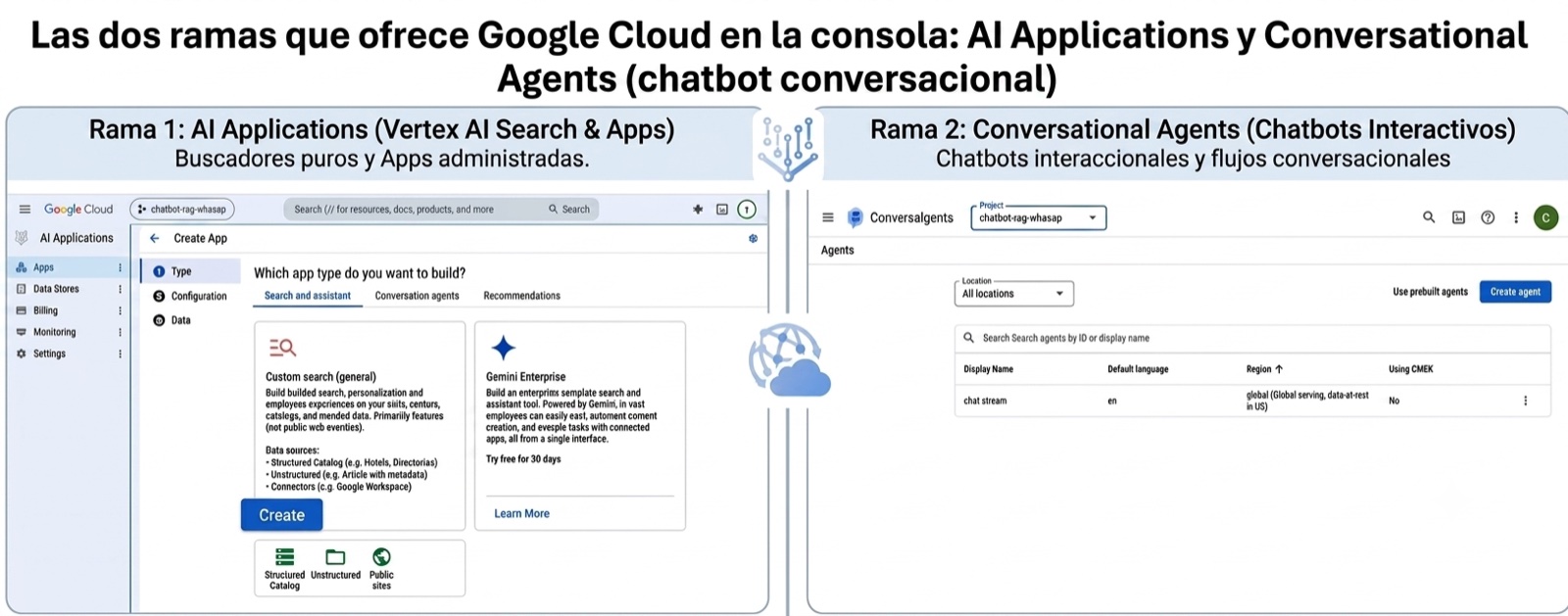
Conversational Agents, Flujos y Playbooks, ¿para qué sirven? No lo sé
¿Y cómo manejamos las conversaciones dentro de estos Conversational Agents en la práctica? Pues tenemos dos opciones según qué tanto queramos automatizar o estructurar la respuesta:
Los Flows (Flujos): es el método clásico heredado de Dialogflow. Diseñas el camino paso a paso como un mapa conceptual (“si dice hola, ve al paso A; si pide precio, ve al paso B”). Es perfecto para cuando necesitas un control estricto y milimétrico de la conversación.
Los Playbooks (Libros de jugadas): esto es lo verdaderamente nuevo de la IA generativa. En lugar de dibujar mapas aburridos, le das instrucciones en texto plano al agente como si estuvieras entrenando a un humano en su primer día: “Tu objetivo es ayudar al cliente, sé amable, usa la información del Data Store y si no sabes algo, no lo inventes”. La IA se encarga de resolver la charla en lenguaje natural siguiendo tus reglas.
Al final del día, todas estas implementaciones forman parte de la estrategia de IA Agents de Google. Pero no olvidemos que el verdadero corazón de todo sigue siendo el Data Store: ese almacén cargado de información para que el agente sepa qué responder. Recuerda no datos no money.
¿Qué creo primero, el chatbot o el Data Store? O sea, ¿el huevo o la gallina?
Me emocioné explicando los productos de Google Cloud, pero acá viene algo sumamente importante: al momento de crear este almacén de datos directamente en Conversational Agents, la plataforma no te permite tener opciones avanzadas para tus datos, como por ejemplo el nivel de actualización, los tipos, etc. Estas opciones avanzadas solo están disponibles cuando creas el Data Store primero, por separado.
Y de ahí viene mi primera recomendación: antes de crear tu chatbot, piensa en lo fundamental, que es de dónde vas a sacar los datos (Recuerda: no datos, no money). De acuerdo a eso, crea el Data Store primero con las opciones exactas que necesites, tales como un refresco de datos tipo streaming (en tiempo real) o programado para cada día. Una vez creado esto por fuera, ahí sí puedes ir a crear tu chatbot en cualquiera de sus formas (sea con un Flujo o con un Playbook) y llamar a tu Data Store.
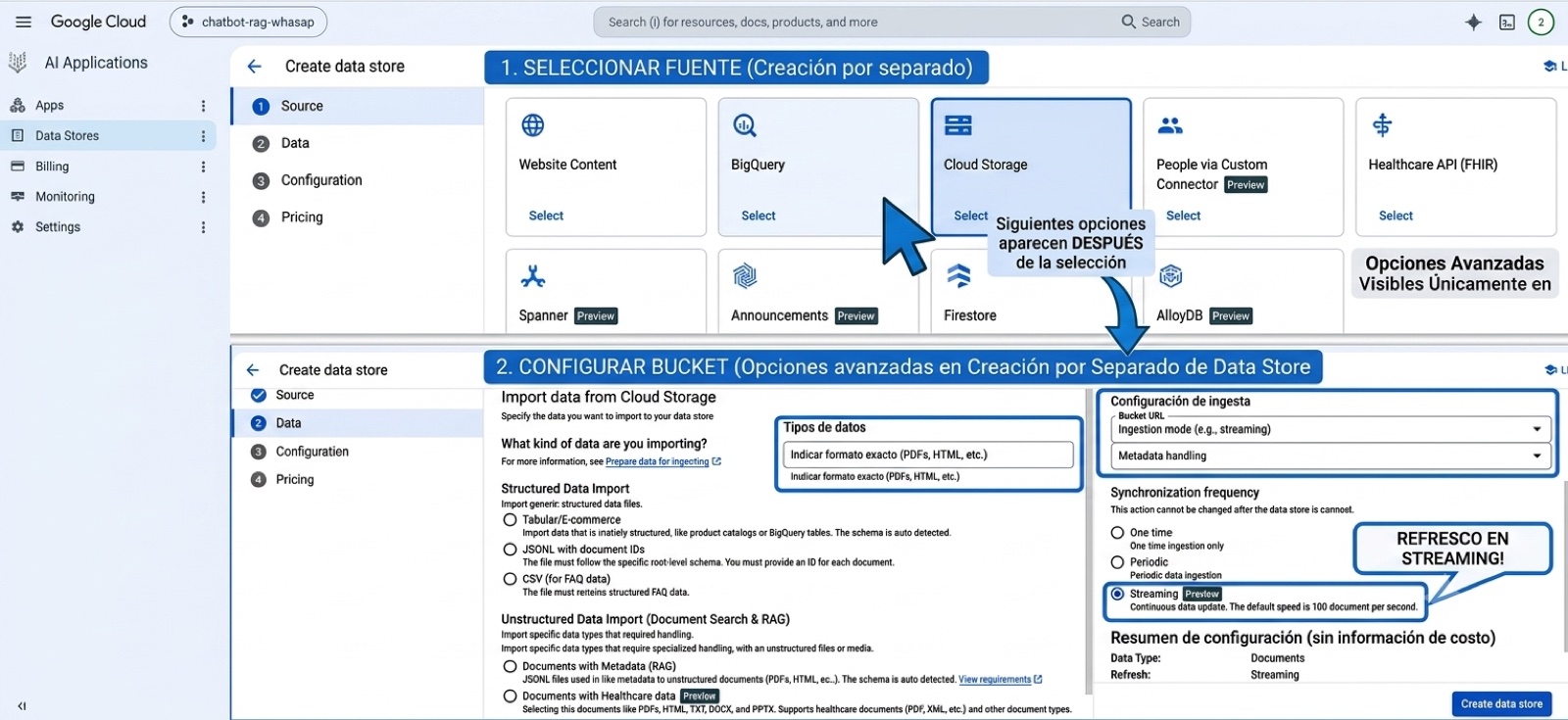
Es un detalle pequeño, ¿no? Pero al menos a mí me costó aprenderlo, y como tenemos esa urgencia de hacer todo rápido, la verdad es que desespera no saber qué pasa y buscar en la documentación y no encontrar una explicación rápida.
Consejos prácticos que parecen obvios pero nada es obvio en la nube
Les comparto algunos consejos:
Primero la arquitectura, luego el código: como en todo buen proyecto, primero construye la arquitectura en papel. Ya que la tengas clara, construye tu Data Store por separado y escoge una de las tantas formas de ingesta que ofrece: sea por API, conectándote a Google Workspace o a un Bucket, o usando bases de datos de Google o de terceros.
Cuidado con el peligro del “Preview”: hay opciones muy atractivas que están en Preview (fase de prueba). Es buenísimo probarlas para conocer el futuro, pero recuerda: están en preview. Esto significa que la opción puede que siga o no, o puede que sufra algún cambio drástico y tu app deje de funcionar si dependes de ella en producción. Es mejor esperar a que salgan a la luz de forma oficial (General Availability) para utilizarlas en producción. Ahora, si nos gusta el peligro, no los juzgo por usarlas en apps productivas, pero definitivamente no es recomendable. (Google Cloud envía correos al administrador del proyecto en el caso que alguna función preview afecte de alguna manera el proyecto)
Aprovecha el patio de Google: utiliza las conexiones que ya están nativas en el ecosistema de Google. De ser posible, hazlo; nos facilita la vida al momento de implementar soluciones. Por ejemplo, la integración con todo el ecosistema de Google Workspace o con las bases de datos de GCP es una maravilla que te ahorra horas de código.
No confundas cuotas con reservas: por último, recuerda algo que ya vimos en un artículo anterior: en el Data Store no colocas cuotas de límite de gasto, lo que haces es “reservar por suscripción”. Así que no te confundas; esas opciones no son para controlar tus gastos diarios aunque lo parezca, solo es para apartar recursos y, dependiendo de qué tanto los utilices, te puede salir más caro.
Después de la tormenta viene la calma en la nube
Y ya superado todo esto, y después de romperme la cabeza entendiendo por qué no podía tener más opciones avanzadas en mi Data Store, finalmente pude tener un chatbot tipo RAG que se alimenta de información que se actualiza en tiempo real. Ese pequeño detalle de crear el almacén de datos primero por fuera me pudo haber ahorrado muchísimo tiempo… pero bueno, es el precio que hay que pagar por estar a la moda de la Inteligencia Artificial.
Una enseñanza más. ¡Nos vemos en el próximo artículo!
Glosario para los que no viven en la nube
RAG (Retrieval-Augmented Generation): técnica donde el chatbot, antes de responder, busca en una fuente de datos real en lugar de responder solo de memoria. Es la diferencia entre responder de memoria y responder con el libro abierto.
Data Store: el almacén de datos del chatbot. Es donde vive toda la información que el agente va a consultar para responder — puede ser documentos, páginas web, bases de datos, etc.
Streaming: actualización de datos en tiempo real, sin esperar. Como ver un partido en vivo en lugar de ver el resumen al día siguiente.
API: una puerta de acceso entre dos sistemas. En lugar de que tú le pases datos manualmente, la API los transfiere automáticamente entre aplicaciones.
Bucket: un contenedor de archivos en la nube. Imagina una carpeta gigante que vive en internet y que otros servicios pueden leer directamente.
Preview: fase de prueba de una funcionalidad. El producto existe y funciona, pero Google todavía puede cambiarla o eliminarla sin previo aviso. No es recomendable depender de ella en producción.
General Availability (GA): cuando una función sale oficialmente al mercado. Ya no es experimento: Google la soporta formalmente y es seguro usarla en producción.
Playbook: instrucciones en texto plano que le das al agente para que sepa cómo comportarse. En lugar de diseñar un flujo visual, le escribes las reglas como si le explicaras a una persona nueva en su primer día de trabajo.
ENTRADAS POPULARES
- El corazón de los chatbots: qué es realmente un Data Store en Google Cloud
Cómo funcionan los Data Stores en Google Cloud para chatbots tipo RAG, por qué hay que crearlos primero por fuera y qué evitar en producción.
-
 Enviar millones de correos y no morir en el intento
Enviar millones de correos y no morir en el intentoLo que aprendí tratando de enviar millones de correos al mes, misión imposible o posible si lo hacemos bien
-
 ¡Prueba y error en la nube no es buena idea!
¡Prueba y error en la nube no es buena idea!GCP Search Chatbot: pay as you go o reservar recursos
-
 IA, Next.js 15.x y la crónica de un cryptojacking-cidio
IA, Next.js 15.x y la crónica de un cryptojacking-cidioCómo una 'simple versión' desactualizada de un paquete (aproximadamente 1 año) puede ser utilizada para vulnerar tu aplicación y hacer rico a otros.
-
 Claude Code, Opus o Sonnet: 100 dólares bien invertidos o mal gastados
Claude Code, Opus o Sonnet: 100 dólares bien invertidos o mal gastadosUsé Opus para diseñar y construir toda mi aplicación, ya que sentía que Sonnet era menos listo y podía romper algo
-
 Utilizo Claude Code o Antigravity, no los dos juntos
Utilizo Claude Code o Antigravity, no los dos juntosSi utilizo Claude Code no puedo usar Antigravity, Gemini no contesta ni hace nada.
-
 Optimizando Costos en GCP: proformar no es lo mismo que estimar consumo
Optimizando Costos en GCP: proformar no es lo mismo que estimar consumoDescubre cómo reducir tu factura de Google Cloud Platform sin sacrificar rendimiento. Estrategias del día a día.
Comentarios
¿Preferés no usar GitHub? Únete al Discord y comenta ahí.